

Bedrockのナレッジベースは1アカウントにつき50個までしか作成できません。ユーザー単位にナレッジベースを作成するような使い方はできません。1つのナレッジベースに複数のユーザーの情報を覚えさせようと思うとユーザー単位に問い合わせを行う必要があります。今回はその方法について解説します。
Bedrockのナレッジベースとは
BedrockはAWSから生成AIを呼び出すサービスです。生成AIでLLMが学習していない知識について回答させる場合、RAGを構築する必要があります。ナレッジベースはBedrockで簡単にRAGを構築するための機能です。
ナレッジベースの構成
データソース
RAGで覚えさせるための知識データを格納する場所です。2024年8月時点ではS3のみが正式に機能提供されています。それ以外はPreviewですがWebクローラーとサードパーティーのConfluenceとSalesforceとSharepointが選択できます。S3の指定はバケット単位ではなくURI単位になっています。プレフィックスを指定することも可能です。データソースは最大5つまで設定することができます。
埋め込みモデル
データソースに格納したデータをベクトルに変換するための埋め込みモデルは2024年8月時点では以下の3つを選択することができます。
- Titan Embeddings G1
- Embed English v3
- Embed Multilingal v3
ベクトルデータベース
埋め込みモデルによりベクトルに変換されたデータを格納するデータベースを指定できます。クイック作成と事前に作成したデータベースの2つから選択できます。
クイック作成を選択すると必要な設定が行われたAmazon OpenSearch Serverlessを作成してくれます。しかし、開発目的で本番のワークロードでは使用することはできません。
事前に作成する場合、以下のサービスから選択可能です。サービスによって設定しておく項目が変わってきます。
- Amazon OpenSearch Serverless 用ベクトルエンジン
- Amazon Aurora
- Pinecone
- Redis Enterprise Cloud
管理コンソールでの構築
 データソースを選択します。
データソースを選択します。



S3のデータソースをフィルタリングする方法
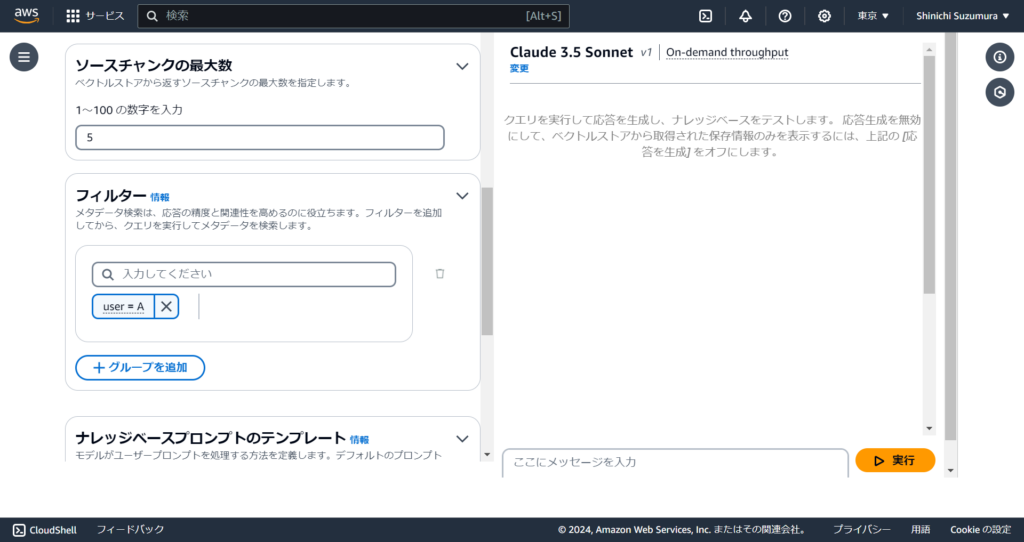
例えばS3に複数のユーザーで知識ファイルを格納したとします。Aさんの知識ファイルをBさんには見せたくないという場合、Aさんからの問い合わせの場合はAさんが作成した知識ファイルのみ、Bさんからの問い合わせの場合はBさんが作成した知識ファイルのみを使用して回答させる必要があります。
最初はユーザー単位にナレッジベースを作成しようと考えたのですがナレッジベースを50個しか作成できないということで断念しました。次にユーザー単位にプレフィックスを指定してデータソースを分けようと考えましたが1つのナレッジベースに5つのデータソースしか作成できないということでこちらも諦めました。
たどり着いたのがメタデータによるフィルタリングです。Aさんが作成した知識ファイルにはuser=Aというメタデータを作成し、Aさんからの問い合わせにはuser=Aでフィルタリングした知識ファイルのみを使用して回答させます。
メタデータの作成方法
ナレッジベースのフィルタリングに使用するメタデータはS3のメタデータの機能とは別になります。S3オブジェクトと同じ名前で拡張子が.metadata.json というファイルを作成してその中にメタデータを記述します。.metadata.jsonの中身は以下の書式になります。
{
"metadataAttributes": {
"user": "A"
}
}私はS3のイベント通知でファイルが作成するタイミングでLambdaを呼び出し自動でメタデータを作成するようにしました。
メタデータでフィルタリング
SDKからは以下のコードで実行することができます。
# Bedrockクライアントの作成
client = boto3.client("bedrock-agent-runtime")
# フィルター作成
metadata_filter = {
"equals": {
"key": "user",
"value": user
}
}
# フィルタリング実行
response = client.retrieve_and_generate(
input={"text": f"プロンプト"},
retrieveAndGenerateConfiguration={
"type": 'KNOWLEDGE_BASE',
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "ナレッジベースID",
"modelArn": "使用する生成AIモデルのARN",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": metadata_filter
}
}
},
},
)
管理コンソールから試す場合は以下のようにフィルターを設定します。
まとめ
生成AIを業務活用するのに手軽に導入できるのはRAGです。Bedrockで簡単にRAGを構築するにはナレッジベース。RAGは回答の精度も重要なので、今回紹介したユーザーによるフィルタリング以外にもデータをメタデータでカテゴライズして質問にあったカテゴリーでフィルタリングすることで精度を上げることもできます。この記事を参考に精度の高いRAGを構築してみてください。








コメント