

AWS re:Invent 2024にてBedrockがRerankモデルのサポートを開始したと発表がありました。勉強中のLangChainに早速取り込んでみました!
Rerankモデルの有効化
Bedrockでモデルを使うには有効化が必要です。
今回新たに使えるようになったのはAmazonのRerank 1.0とCohereのRerank 3.5です。どちらも東京リージョンで利用可能です。
rerank関数を自作
CohereのRerankモデルだとCohereRerankという専用のクラスがLangChainで準備されていますが、Bedrockではリランク用のクラスは用意されていません。そこでboto3を使ってBedrockのRerankモデルを呼び出してリランクする関数を自作してchainに組み込みます。
シンタックス
関数のシンタックスはこんな感じです。
def rerank(inp: dict[str, Any], top_n: int = 3) -> list[Document]:
"""
この関数はmazon.rerank-v1:0モデルを用いてリランキングします。
Args:
inp (dict[str, Any]): リランクするための入力データを含む辞書。
- "question" (str): ドキュメントをリランクする基準となる質問。
- "documents" (list[Document]): リランク対象となるドキュメントのリスト。
top_n (int): リランク後に上位から返されるドキュメントの数。デフォルトは3。
Returns:
list[Document]: 与えられた質問に基づいてリランクされたドキュメントのリスト。
"""質問をquestion 、リランクするドキュメントのリストをdocuments で受け取ります。上位何番目まで取得するかを指定するtop_n はオプションでデフォルト値は3です。
Bedrockの呼び出し
Bedrockを呼び出す際、bodyはJSON形式で渡す必要があります。しかし、DocumentはJSONシリアライズできないのでそのまま渡すとエラーになります。そこでDocumentからpage_content を抜き出して配列にしてから設定する必要があります。
question = inp["question"]
documents = inp["documents"]
# AWSクライアントの設定
client = boto3.client('bedrock-runtime', region_name='ap-northeast-1')
# documentsからpage_contentを抽出
document_contents = [doc.page_content for doc in documents]
# リランク
response = client.invoke_model(
modelId="amazon.rerank-v1:0",
body=json.dumps({
"query": question,
"documents": document_contents,
"top_n": top_n
})
)結果の取り出し
AmazonのRerank 1.0の戻り値はindex とrelevance_score の2つだけです。そのため、index からpage_content を逆引きしてDocumentを生成する必要があります。
# レスポンス処理
response_body = json.loads(response['body'].read())
ranked_results = response_body.get('results', [])
# 結果をDocumentのリストに変換
ranked_documents = [
Document(
page_content=document_contents[result['index']],
metadata={"relevance_score": result['relevance_score']}
)
for result in ranked_results
]
return ranked_documentsこれでrerank関数は完成です。
LangChainに組み込む
LangChainには以下のように組み込みます。LangChainの処理については別途解説します。
rerank_rag_chain = (
{
"question": RunnablePassthrough(),
"documents": retriever,
}
| RunnablePassthrough.assign(context=rerank)
| prompt | model | StrOutputParser()
)
output = rerank_rag_chain.invoke("LangChainの概要")
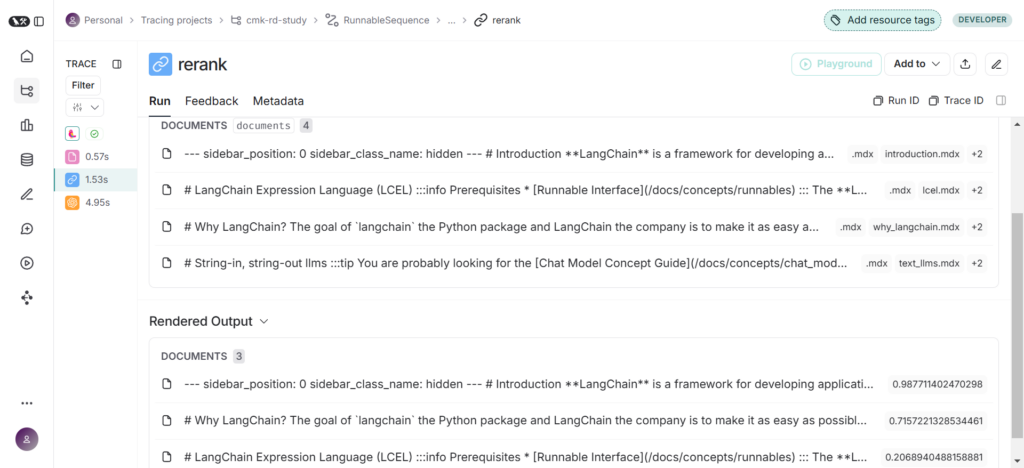
print(output)実行結果をLangsmithで確認するとリランクされていることが確認できます。
まとめ
BedrockのRerankモデルは出たばかりです。LangChainで使用することを考えている人たちの助けになれば幸いです。
AIエージェントを絶賛学習中です。『LangChainとLangGraphによるRAG・AIエージェント[実践]入門』の6.4 検索後の工夫 の章でリランクを取り扱っています。書籍ではCohereを使用するのですがCohereのアカウント持ってないし、Bedrcokで新しいモデルが使えるようになったので試してみようと思いました。
学習を初めて3日目くらいですが、『LangChainとLangGraphによるRAG・AIエージェント[実践]入門』はとても分かりやすいです。AIエージェントに興味がある方は読んでみてはいかがでしょうか? 一緒に学習しましょう!








コメント